Introduction
Today’s LLMs suffer from “slop”, which we define as the repetitive, predictable and robotic text output that makes the text not only of inferior quality but also recognizable and bland. Suppressing such patterns appears an obvious solution but it is not. It further damages the output by killing other useful words, e.g. banning a word “indigestible” will also ban the words like “in”, and “digest” making the text meaningless. Suppression may also introduce a “backfire effect” — if we forbid a term or concept while prompting, the model can accidentally prioritize it by talking about it more.
This post (based on original research) presents a solution to this problem, by achieving 90% “slop reduction” from its outputs. We have provided a framework that combines three innovations to detect and replace the overused patterns. The framework can eliminate 8000 patterns without degrading the output. The framework includes,
- The anti-slop sampler that uses back-tracking for the repetitive words and forces the model to select a new and more human-like word.
- An automated pipeline that identifies "slop" by calculating the frequency ratio of words and phrases in the model output versus human baselines. We have used two baselines; the first is wordfreq library and the second is a human-written text corpus from Reddit and Project Gutenberg.
- Final token-preference optimization (FTPO) is a training algorithm that looks at the exact token where the model has chosen a “sloppy” word. It then adjusts only those specific logits by implementing many “soft-touch” mechanisms along the way.
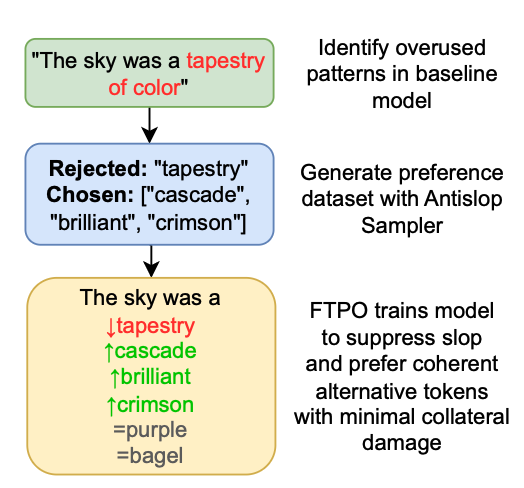
Fig 1. Anti slopping pipeline
Current strategies
Below is a list of current strategies that can reduce repetitive patterns or slop.However, while each strategy possesses unique features, they all have their own shortcomings. Here is a table:
| No. | Strategies | Shortcomings |
1 | Top-k, top-p, and min-p | Don’t address repetitive tendencies in coherent outputs. |
2 | RLHF | Slow and less productive. |
3 | Exclude top choices (XTC) | Targets only high probability tokens. |
4 | Don’t repeat yourself (DRY) | Can’t identify statistically emerging repetitive patterns. |
5 | String banning feature of ExLlama | Hard-bans a provided set of strings at inference time. |
6 | Beam search | Exclude forbidden words or phrases by beam pruning. |
7 | Direct preference optimization (DPO) | Lowers the likelihood of preferred responses, inducing diversity collapse and reducing syntactic and n-gram variety in outputs. |
Slop analysis
Every model is different, having some inherent tendencies; we wanted to explore what those are in more depth. To do this, we collected overly used words and n-grams that are responsible for producing slop patterns using the frequency ratio. An n-gram is a sequence of n consecutive items (usually words, sometimes characters) from the text. The frequency ratio was calculated based on the following formula:
\[ \rho(\mathbf{p}) = \frac{f_{\text{LLM}}(\mathbf{p})}{f_{\text{human}}(\mathbf{p})} \]
\[ f_{\text{LLM}}(\mathbf{p}) \text{ - frequencies of pattern } (\mathbf{p}) \text{ in LLM} \]
\[ f_{\text{human}}(\mathbf{p}) \text{ - frequencies of pattern } (\mathbf{p}) \text{ in human corpora} \]
We generated more than 2000 outputs using creative writing prompts from Reddit and discovered various overrepresentations in different language models.
The innovative sampler
The job of a sampler in LLMs is to select the next token from the probability distribution. The sampler controls creativity, diversity and the coherence of the model’s output.
Our innovative sampler triggers only after the entire sequence of words appears in the inference trace. It works as follows:
As the model generates the output for certain input, our algorithm keeps the trace of tokens and logit distributions. It scans for unwanted patterns after each token. Once such a pattern is detected, instead of suppressing it the algorithm backtracks to its origin and lowers the initiating probability by the configurable ban-strength parameter “s” defined as:
\[ \mathbf{p}_{\text{new}} = \mathbf{p}_{\text{old}} \times 10^{-10s} \]
\[ \text{Where, } 0 \leq s \leq 1.0 \]
The next step is to use the min-p filtering to constrain the adjusted distribution. This step selects the coherent candidates who meet the predefined probability threshold. Our anti-slop backtracking algorithm is as follows:
Fig:2 Anti-slop backtracking algorithm
The final step is soft banning, where we allow only those banned patterns through the forward pass having high probability distribution. The mechanism provides incremental control through the ban-streangth parameter “s”. When s = 0, then patterns are allowed freely. Values between zero and one provide incremental suppression of the banlist, while s = one enforces complete suppression.

Fig 3: Example of soft banning technique
The anti-slop backtracking mechanism detects unwanted patterns in the inference phase, backtracks to the first token of that banned sequence and lowers its probability. It then resamples.
Fig 4: The anti-slop backtracking process
The limitation of this sampler process is that performance degrades by 69-96% due to frequent backtracking. The size of the banlist from 1000 to 8000 also plays a crucial role in performance degradation. A banlist of this size would be overkill for most real-world models; backtracking is resource intensive. Further performance losses may be observed with sampler techniques used in API implementation.
Final token preference optimization (FTPO)
FTPO is a training algorithm designed to avoid loss of performance due to banlist and backtracking used in anti-slop sampler. The sampler detects bad tokens and backtracks repeatedly, which drastically reduces throughput. But the root problem is that the model itself still assigns high probability to those unwanted tokens.
FTPO fixes this by training the model to avoid those tokens directly, so the need for backtracking largely disappears. Instead of retraining the entire sequence, FTPO adjusts the model only at the exact decision point where the error occurs, pushing down the rejected token and favoring better alternatives. This results in a permanent, internalized suppression of bad patterns while minimizing damage to overall model quality. We’ve essentially turned a slow runtime into a fast throughput by learned behavior.
How FTPO works
FTPO works on logits. That’s why it gives precise, local control “delicately” without disturbing the entire token distribution. (A logit is the raw score for each possible token before converting it into probability.) An important part of the FTPO method is the calculation of three loss terms. Here’s how:
1. Preference loss with margin
This pushes the chosen token above the rejected one by a certain margin (m):
\[ L_{\text{pref}} = \frac{\sum_{c \in C} \omega_c \cdot \text{softplus}(m - \Delta_c)}{\sum_{c \in C} \omega_c} \]
\[ \Delta_c = y[c] - y[r] \text{ It is the logit gap between chosen and rejected token.} \]
\[ \text{When } \Delta < 0 \text{ (chosen losing), the penalty is large. As } \Delta \text{ increases toward the} \]
\[ \text{margin } m \text{, the penalty smoothly tapers. Once } \Delta \geq m \text{, the weight goes to zero} \]
\[ \text{and the preference loss no longer contributes.} \]
\[ \omega_c = \text{clamp} \left(\frac{m - \Delta_c}{m}, 0, 1\right) \text{ deactivates the loss when the margin is achieved.} \]
2. Target regularization
This acts on chosen and rejected tokens. It keeps them close to the pre-defined reference. It allows a small free region ( \(\tau_{\text{target}}) \) before the token is penalized.
\[ L_{\text{target}} = \frac{1}{|T|} \sum_{j \in T} \max(|y[j] - y_{\text{ref}}[j]| - \tau_{\text{target}}, 0)^2 \]
\[ \text{where,} \] \[ T = C \cup \{r\} \text{ contains all target tokens} \]
3. Non-target regularization
This anchors all other tokens to the reference. It prevents unintended changes in unrelated parts of a vocabulary.
\[ L_{\text{nontarget}} = \frac{1}{|N|} \sum_{j \in N} (y[j] - y_{\text{ref}}[j])^2 \]
\[ \text{Where,} \] \[ N \text{ are all nontarget tokens} \]
Total loss
\[ L_{\text{FTPO}} = L_{\text{pref}} + \lambda_{\text{target}}L_{\text{target}} + \lambda_{\text{nontarget}}L_{\text{nontarget}} \] \[ \text{Where,} \]
\[ \lambda_{\text{target}} \text{ and } \lambda_{\text{nontarget}} \text{ are weighting coefficients} \]
There are three principles of design that makes FTPO effective.
Logit-space operation: FTPO applies MSE loss to the raw "logits" (scores). This allows the model to target and change only the specific "chosen" and "rejected" tokens without disturbing unrelated parts of the vocabulary.
Margin deactivation: FTPO uses margin m. Once the gap between the good token and the bad token is wide enough, a weight variable \(w_c\) automatically drops to zero. This stops the training for that specific pair, thus preventing overtraining.
Two-part regularization: FTPO uses the two-part MSE loss that allows target logits to move relatively freely, while constraining the remaining vocabulary to the reference. This allows training to high preference accuracy while avoiding destructive logit divergences.
FTPO training
The diagram below shows the entire process of training data for FTPO:
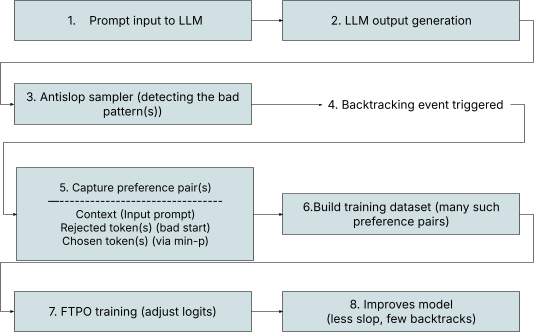
Fig. 5: Anti-slop sampler and FTPO training
Why is FTPO superior?
The graph visualizes the performance of FTPO banlist suppression against four methods; token banning, antislop sampler, DPO and Gemma3 -12b baseline. Banlist suppression for each method is plotted against output degradation as measured by our writing rubric. The Writing-Quality Rubric is an automated evaluation framework designed to objectively measure the structural and stylistic integrity of generated text. Instead of relying on human graders, it uses a high-capacity model (GPT-5) to score outputs based on four specific dimensions:
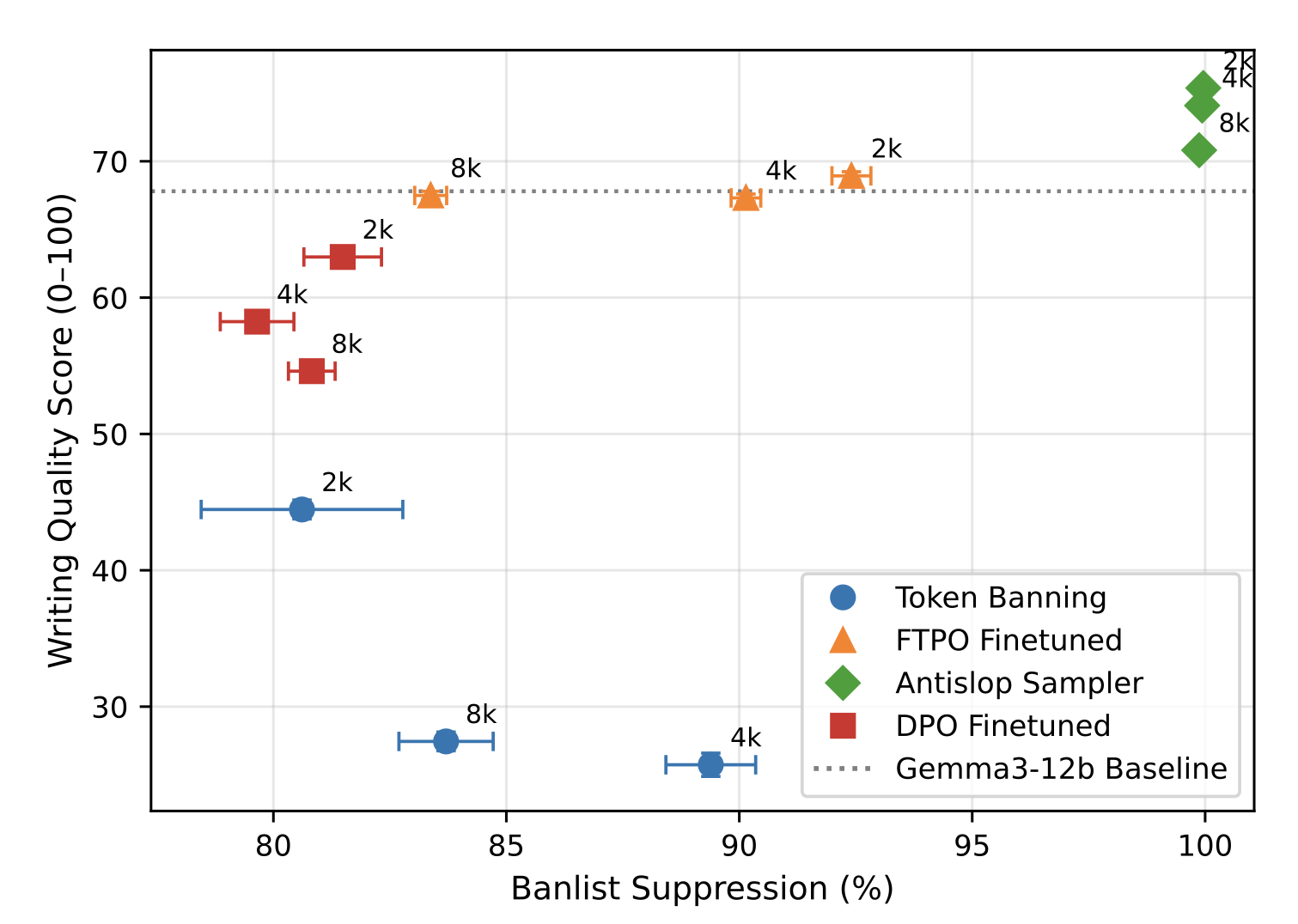
Fig. 6: FTPO comparison
FTPO achieves 90% slop suppression with minimal quality loss, outperforming DPO and token banning. The figure 6 evaluates four suppression methods on gemma-3-12b across banlist sizes of 2k, 4k, and 8k patterns. FTPO maintains baseline writing quality while suppressing 85-90% of unwanted patterns. In contrast, DPO degrades quality by 6-15 points despite achieving only 80-82% suppression. Token banning shows catastrophic quality collapse. Error bars show 95% confidence intervals (\(CI_{95}\)). n= 1,000 outputs per condition.
The table below provides a comparison between FTPO and DPO:
Table 2: FTPO vs. DPO
No | Parameter | Result |
1 | Suppression effectiveness | FTPO achieves 8.5% stronger suppression than DPO. |
2 | Capability preservation | FTPO maintains math reasoning on GSM8k and world-knowledge capabilities on MMLU within 1-3% of baseline. DPO degrades both metrics by 2-5%. |
3 | Long-form generation | FTPO-trained models cluster around the baseline gemma3 score for 2k, 4k and 8k banlist sizes; while DPO experiences a large degradation in quality. |
4 | Lexical diversity | FTPO maintains or enhances diversity (95-102% of baseline), while DPO causes progressive collapse (74-92%). |
5 | Training Gemma3-12b model | FTPO can train to nearly 100% preference accuracy with minimal degradation, while DPO only manages 40%, after which substantial degradation. |
Comparing FTPO and DPO provides us with some interesting results.
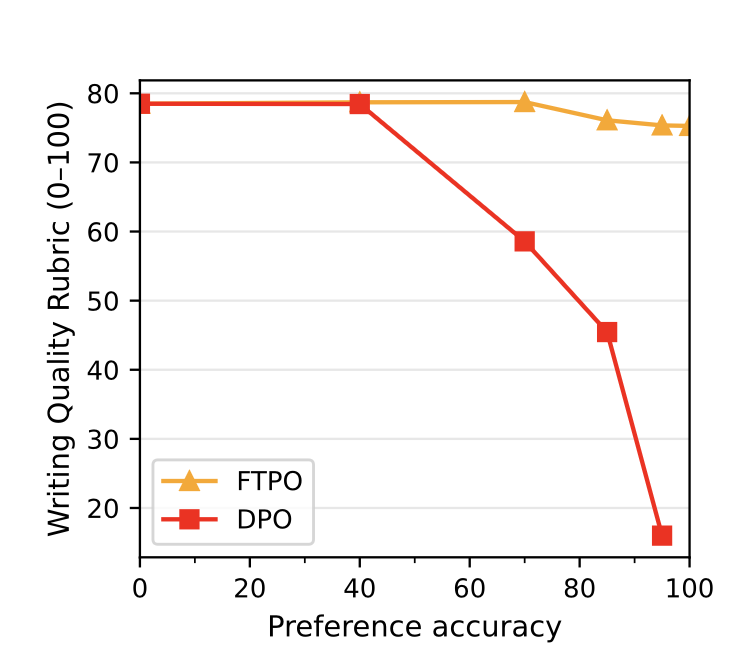
Fig.7. FTPO maintains writing quality as training progresses to higher preference accuracies, while DPO degrades sharply after the 40% accuracy mark. This experiment trains gemma-3-12b on a banlist of 1,000 items.
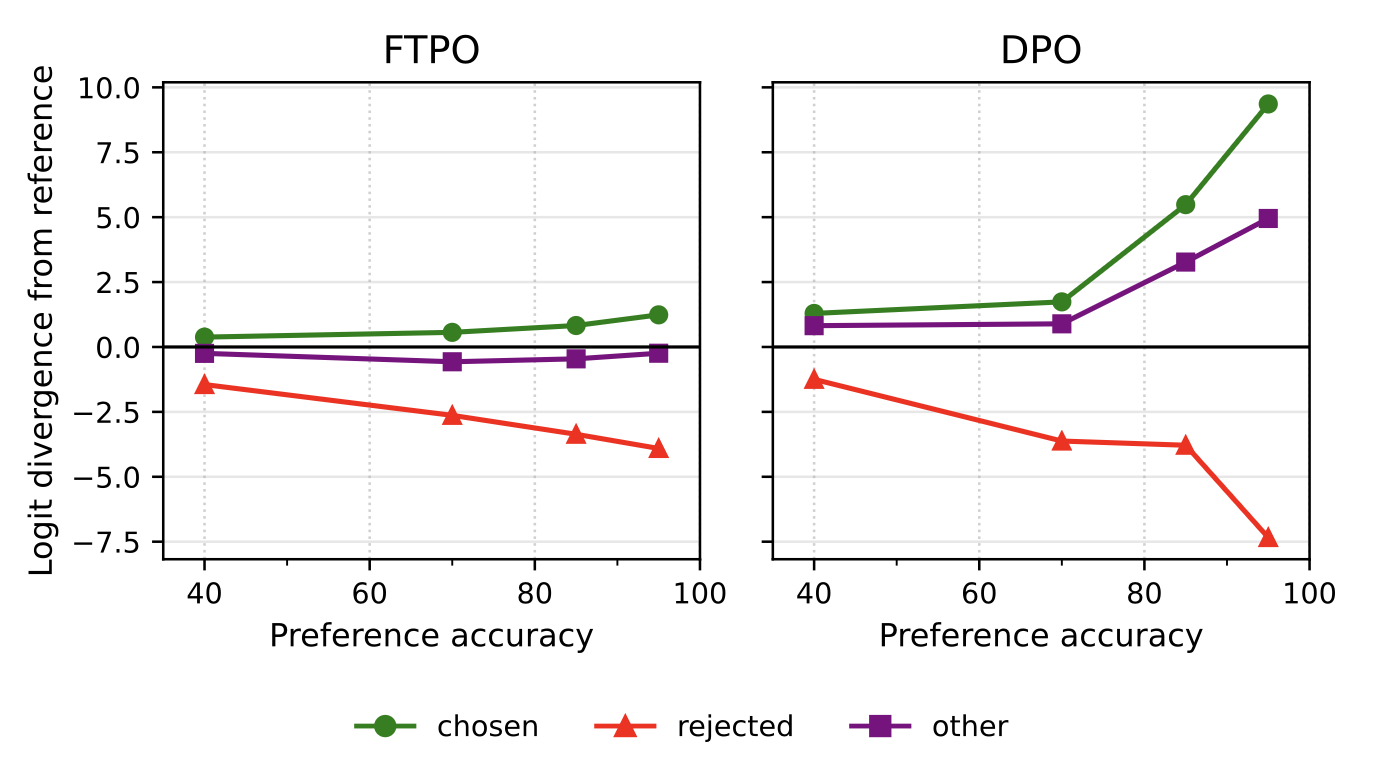
Fig 8: With FTPO, logits stay close to reference due to (1) the MSE loss terms and (2) the early switch-off feature which nulls the training signal for chosen tokens that are already winning vs rejected.
Conclusion
The anti-slop sampler reduces throughput by 69-96% for the banlist sizes of 1k to 8k due to frequent backtracking. We developed a pipeline that automatically profiles a model’s overused writing patterns, generates a training set and trains the model to suppress these patterns. Our FTPO trainer is designed to make targeted adjustments to the model’s over-used writing tendencies with minimal changes to its distribution.
Across our tests, FTPO and the sampler achieved higher suppression than DPO and logit-based token banning, with negligible measurable quality loss on our rubric. We release code and datasets under the MIT license.
Deep dive
For more detailed information on our experiment and its results please refer to the original paper: Antislop: A comprehensive framework for identifying and eliminating repetitive patterns in language models.
Explore the code in more depth on Github.