A robust LLM decoding strategy that is hyperparameter-free, entropy-aware and information-theoretic.
In this research paper, we introduce a novel approach of sampling named \(\rho\)-less sampling for text generation in autoregressive models. We discuss what such models are and why this sampling technique is valuable for the AI/ML practitioners. We’ll begin by exploring autoregressive models and then provide a comparison of existing sampling techniques — and what \(\rho\)-less sampling offers that’s different.
Autoregressive models
A transformer-based large language model LLM is, at a basic level, a software system that takes in text and generates text in response. Once a large enough model is trained on a large, high quality big data, it should be capable of generating useful outputs. The interesting part is that the model doesn’t generate the entire text in one go; instead, it generates a single token at a time. Each single token generation step is called a forward pass. After each token is generated, the model’s output is appended to its input prompt. The model then generates the next token and it’s presented to the model again for another forward pass. This goes on sequentially. These models are known as autoregressive models.
Decoding strategy and sampling
Autoregressive models contain three components: the tokenizer, the stack of transformers and the language model (LM) head. The first and the last components are particularly relevant for our discussion here. The tokenizer breaks the text into a sequence of token-ids that then become the input to the neural network — a stack of transformers that do all the processing. The output layer is LM head; this translates the output of the stack into the probabilities of the token distribution for the next token. The method through which a single token from the probability distribution is chosen is called a decoding strategy. The impressive capabilities of modern LLMs have been aided by advancements in sampling-based decoding strategies. There are a number of approaches but we’ll discuss one in particular in this post - the \(\rho\)-less sampling.
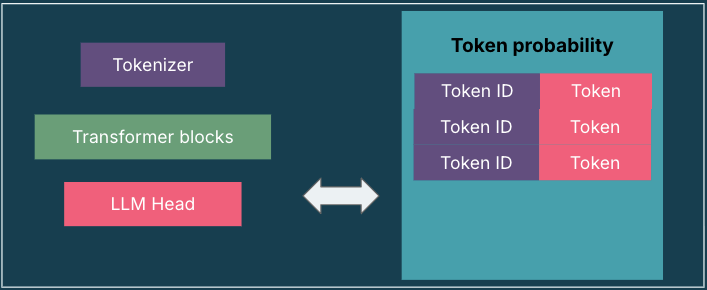
Diagram - 1
The diagram illustrates the overall architecture of the transformer-based LLM and its decoding process. After completing the forward pass, the model outputs a probability distribution over all tokens in the vocabulary. (ref: Jay Alammar et al.)
Comparing existing popular decoding strategies
Before we explore \(\rho\)-less sampling in more detail, let’s first look at a number of other popular decoding strategies. This will help us understand the uniqueness and the advantages of \(\rho\)-less sampling technique.
While decoding the text, the model excludes low probability tokens because they disrupt the coherence of the output. Top-\(\kappa\) sampling limits sampling to the \(\kappa\) most probable tokens. However, this leads to incoherence in the output when the probability distribution is peaked or very uniform. Top-\(\rho\) sampling samples form the highest-probability tokens whose cumulative probability exceeds the threshold -\(\rho\), whereas the -sampling truncates all tokens with probabilities below a cut-off threshold . But both techniques lack the ability to adapt to high entropy conditions where temperature is high. Such conditions occur frequently when output diversity is needed.
Another sampling technique called -sampling defines the threshold as the minimum of and a scaled negative Shannon entropy exponential quantity. But this needs additional hyperparameter tuning; it also assumes a uniform distribution baseline which may differ significantly from the true distribution. This means we need to control randomness in a way that keeps the output text fluent but interesting. The above methods don’t adapt dynamic thresholds to model’s token distribution changes at each step.
That’s where Mirostat and min-\(\rho\) sampling comes in. Mirostat sampling is a feedback-based decoding technique that assumes token probabilities follow Zipf’s Law; it dynamically adjusts its sampling threshold based on an acceptable level of unpredictability and uses a learning rate to control the adjustment speed. Min-\(\rho\) sampling defines the truncation threshold as a fraction of the maximum token probability, introducing a single scaling hyperparameter. This approach improves stability under high-temperature decoding, but remains sensitive to hyperparameter tuning and relies on a single-point statistic of the token probability distribution. This limits its adaptability.
Why do we need a new decoding strategy?
The main idea behind \(\rho\)-less sampling is to make token selection during LLM decoding more deliberate and data-driven, as opposed to arbitrary methods like the ones mentioned earlier. Why not leverage the entire probability distribution? Imagine randomly selecting a token, and it just happens to be the correct one (according to the ground truth). The expected probability of this event sets a natural threshold — what we call \(\rho\)-less. This approach introduces a new, parameter-free decoding strategy for LLMs that’s based on informed decision-making rather than randomness.
The technique is based on how concentrated or spread the probabilities are. We call it the second moment of the probability distribution.
Mathematically, it can be represented like this: it as follows:
|V| = vocabulary size
M[P] = mean of squared probabilities (the second moment)
\[L[P] : = \sum_{i=1}^{|v|} (P(x_i)^2\]
\[= |V| \times \left\{ \frac{1}{|V|} \sum_{i=1}^{|V|} \left( P(x_i \right)^2 \right\}\]
L[P] = |V| x M[P]
So, L[P] ∝ M[P]
If the distribution is peaked (ie. a few tokens dominate), M[P] is large therefore L[P] is large. This means the model is more confident, so fewer tokens pass the threshold.
If the distribution is flat (i.e. there are many similar probabilities), M[P] is small therefore L[P]] is small. This means there’s greater uncertainty, so more tokens are included.
In short, \(\rho\)-less adapts automatically to model output entropy.
The technique dynamically adjusts the truncation threshold at each time-step using the entire token probability distribution. The concept is grounded on solid foundations of information theory. Information theory is a field that studies how to measure and manage uncertainty in probability distributions. Its core idea is that uncertainty can be quantified—and the popular approach is through entropy, which tells us how unpredictable a distribution is (high entropy = more uncertainty, low entropy = more confidence).
The \(\rho\)-less sampling takes advantage of this idea by using the expected probability of correctly guessing the next token — as its truncation threshold. This expectation depends directly on the entropy of the model’s output distribution. So:
When entropy is low (model is confident), the expected correct probability is higher, and \(\rho\)-less sets a higher threshold.
When entropy is high (model is uncertain), the expected correct probability is lower, and \(\rho\)-less sets a lower threshold.
- However, the alternative techniques, who do not use this technique, suffer from text degeneration because they do not consider the entropy of the entire probability distribution while computing the threshold. The technique doesn’t impose parametric assumptions or need hyperparameter tuning, which offers a robust model-agnostic threshold — even including in unpredictable situations.
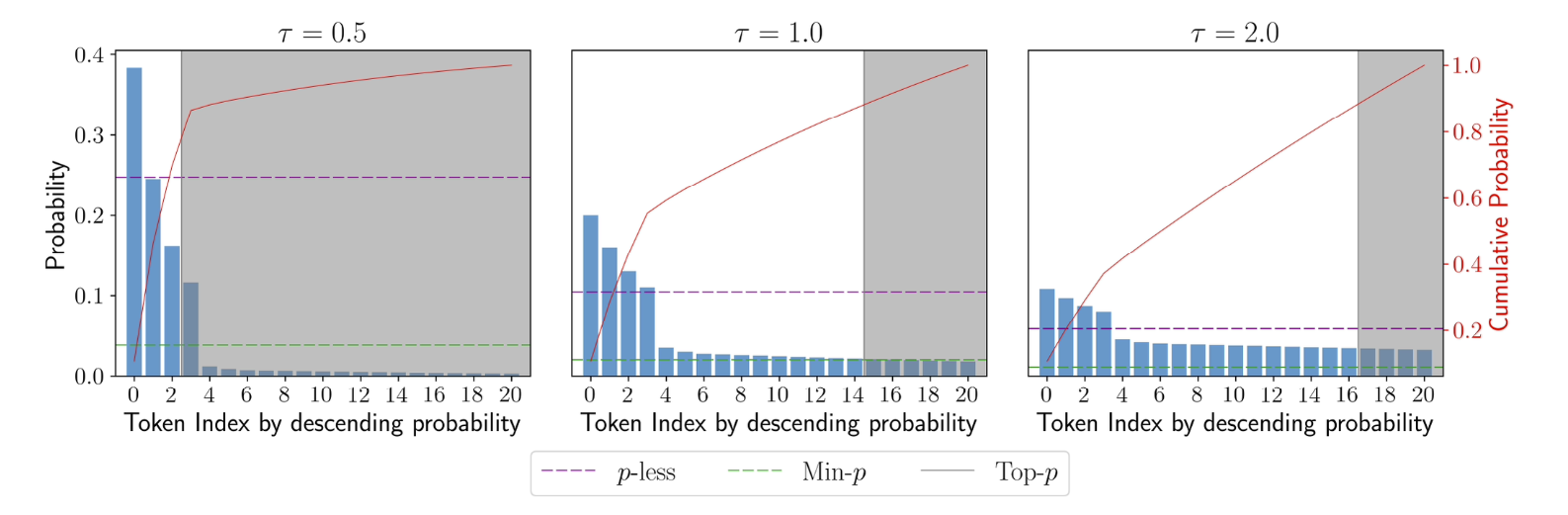
Figure: 1
A comparison of truncation thresholds produced by -less, min-, and top- for token probability distribution with different applied temperatures (). As temperature increases, -less avoids admitting a large number of lower-likelihood tokens by considering the entropy of the distribution in computing the threshold.
\(\rho\) -less is practically effective while strongly interpretable with theory. Specifically, \(\rho\)-less is compatible with interpretations in probability theory, entropies and statistical moments — as opposed to other methods that employ fixed heuristic parameters and don’t leverage full information from the LLM output distribution.
\(\rho\)-less is also valid and bounded. It guarantees a threshold that produces a non-empty token sampling set. This is in contrast to other methods that can meet with edge cases. If you’re interested, take a look at the original work for the detailed proof.
How does \(\rho\)-less sampling work?
Before formally describing the technique, let’s try and understand it in a relatively simple way. The \(\rho\)-less sampling dynamically adapts the token selection threshold at each decoding step by leveraging the entire probability distribution. It computes a “correct random guess” likelihood as a principled cutoff, admitting only tokens above this threshold. The method is entropy-aware, which means the higher uncertainty (entropy) expands the candidate set to include lower-probability tokens, while lower uncertainty narrows the set, ensuring a balance between diversity and coherence in generated text.
Let’s now dive a bit deeper to understand the technique at a mathematical level.
V is the set of all possible tokens (model’s vocabulary)
\(v \in V\) is a single token from the vocabulary
At every decoding step t, the model decides the next token.
S represents the sampled token
T represents the true token (the ground truth)
\(\rho(S = v)\) denote the probability that token \(v\) is sampled.
\(\rho(\tau = v)\) denote the probability that token is the correct token in the “ground truth” sense.
We know that,
\(P_{\theta}(v \mid x_{1:t-1})\)
This is the probability the model (with parameters θ) assigns to token \(v\) given the previous context x₁, x₂ ,…,xₜ₋₁ . All the autoregressive models work on this formula
\(L[P_{\theta}]\) defines the model’s predicted token distribution conditioned on the given token sequence x₁:ₜ₋₁ where θ are the language model parameters. It’s the intersection (choosing the token ) of the two sets: the sampling and true distribution as shown here:
\(L[P_{\theta}] := \sum\limits_{v \in V} \rho(S = v \,\cap\, \tau = v \mid x_{1:t-1})\)
This can be expanded as:
\(\sum\limits_{v \in V} \rho(S = v \mid x_{1:t-1}) \; \rho(\tau = v \mid x_{1:t-1})\)
Sampling (S) and correctness (τ) are independent events (no feedback involved). We have access to the predicted token distribution of the language model and no other external augmentation resources; we’ll therefore take it as our best empirical estimate of the true token distribution, i.e.
\(\rho(\tau = v) = P_{\theta}(v \mid x_{1:t-1})\).
So we have,
\(L[P_{\theta}] = \sum\limits_{v \in V} P_{\theta}(v \mid x_{1:t-1})^{2}\)
This is the foundation step of the ρ-less technique.
The \(\rho\)-less sampling technique in few intuitive steps
Based on the above basics, we can define the process of \(\rho\)-less technique as follows:

Diagram - 2
The diagram illustrates the process of \(\rho\)-less sampling technique
Here’s the mathematical explanation of all the steps:
Step 1 :
Determine the threshold probability L[Pθ] using the equation below:
\begin{equation} L[P_\theta] = \sum_{v \in V} P_\theta (v \mid x_{1:t-1})^2 \end{equation}
Step 2:
Construct the sampling set with tokens whose probabilities are at least the threshold probability.
The sampling set is \(V_{\rho\text{-less}}\)
\begin{equation} V_{\rho\text{-less}} = \{ v \in V : P_\theta (v \mid x_{1:t-1}) \geq L[P_\theta] \} \end{equation}
Step 3:
Sample from the set in step two the next token xt , according to the normalized token probabilities \(P'_{\theta}\)
probabilities $P'_\theta$: \begin{equation} P'\theta (x_t \mid x_{1:t-1})|_{x_t:=v} = \frac{P\theta (v \mid x_{1:t-1})}{\sum_{v' \in V_{\rho\text{-less}}} P\theta (v' \mid x_{1:t-1})} \end{equation} for \(v \in V_{\rho\text{-less}}\)
The \(\rho\)-less-norm sampling extension
\(\rho\)-less-norm extends \(\rho\)-less by relaxing the sampling threshold. It does this by subtracting the normalized likelihood of an incorrect random guess, allowing the model to admit a broader set of candidate tokens. The result is a decoding behavior that prioritizes diversity over strict coherence, making it well-suited for creative or exploratory generation tasks.
The p-less\(_{\text{norm}}\) is denoted by \(\overline{L}[P_{\theta}]\)
\(\overline{L}[P_{\theta}] := L[P_{\theta}] - \frac{1}{|V|-1} \times \sum_{u, v \in V, u, v \neq 0} P_{\theta} (u \mid x_{1:t-1}) P_{\theta} (v \mid x_{1:t-1})\)
(Probability of a randomly sampled and incorrect token)
\(= \frac{|V|}{|V|-1} \, L[P_{\theta}] - \frac{1}{|V|-1}\)
Here, \(\frac{1}{|V|-1}\) gives the ratio of the possible number of correct to incorrect outcomes.
Models and datasets
The \(\rho\)-less sampling technique was performed on the following models to check the consistency of the results as well as the universality of the technique.

The technique was tested using these datasets:
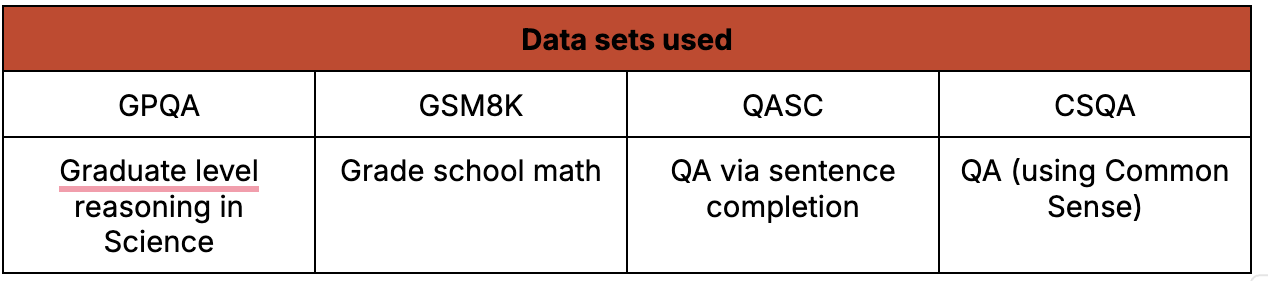
The technique was used to perform the following two tasks using the datasets on the above mentioned models.

We’ll now discuss the results. For a detailed discussion, please refer to the original research paper here.
The \(\rho\)-less sampling technique test results
After testing the \(\rho\)-less sampling technique on three LLMs and five datasets spanning math, logical reasoning and creative writing skills we have proved the following benefits of this new technique:
The technique consistently achieves high accuracy across a wide range of temperature values especially in math and logical reasoning tasks (refer Figure - 2)
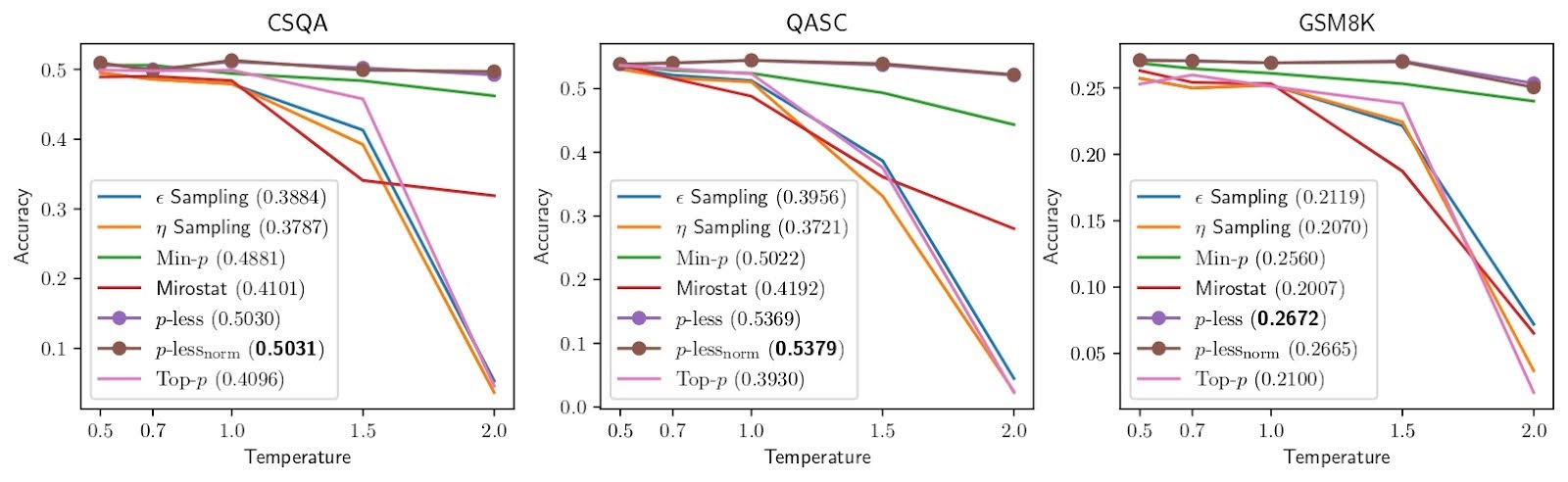
Figure - 2
Accuracy vs. temperature curves of each method for each of the four math and logical reasoning datasets using Mistral -7b. The legend provides AUC values. (The AUC value is an area under the accuracy - temperature curve for each method (normalized between 0.0 and 1.0).
The technique provides best performance in automated evaluations for the writing prompts dataset. This helps for better performance in creative writing.
The technique demonstrates superior inference-time efficiency over the other methods, by offering:
higher token sampling speed and
generating concise text without sacrificing task-specificity.
The technique enforces a form of entropy-aware regularization, mitigating token overcommitment in ambiguous regions and preserving semantic fidelity. (Refer to figure 3)
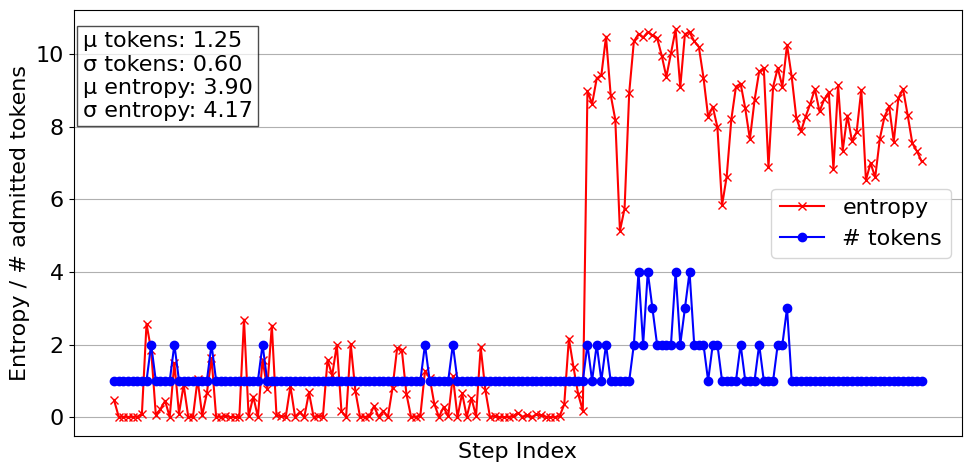
Figure 3
The plot shows step-wise entropy and the number of admitted tokens for a GSM8K question answered with Llama3-70b. Even though entropy is extraordinarily high, the number of admitted tokens remains low. This demonstrates \(\rho\)-less’s selectivity in admitting more tokens and effectiveness in subduing verbosity.
The truncation threshold of \(\rho\)-less sampling dynamically adjusts with temperatures unlike other methods where hyper-parameters aren’t meaningful when the temperatures approach zero or infinity. (refer figure 1)
The \(\rho\)-less and \(\rho\)-less norm produce higher accuracy at a given level of generation diversity than other sampling methods, exhibiting a pareto dominance along the diversity-accuracy frontier. (refer Figure - 4)
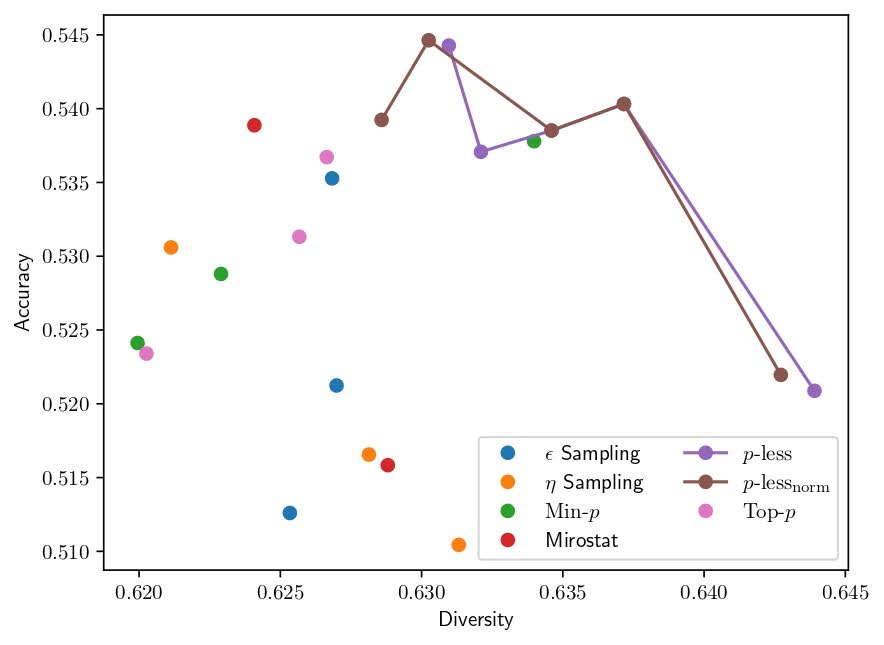
Figure - 4
QASC accuracy vs. diversity for various techniques
Implementation
Keen to implement a \(\rho\)-less method on your own LLM? Please check the link here. The page contains all the necessary information like installation details with examples along with the code snippets you can apply to your LLM. The original research paper can be found here.
Conclusion
We’ve developed \(\rho\)-less sampling, a new approach to sampling-based decoding that does away with hyperparameter tuning altogether. Instead of forcing practitioners to hunt for the “right” cutoff, \(\rho\)-less brings the best qualities of existing sampling techniques together under one unified method.
Across three LLMs and four very different datasets — from math and logical reasoning to creative writing — \(\rho\)-less delivered consistently strong results, even as temperature settings changed. Other decoding strategies, by contrast, tended to fall off a cliff as temperature increased.
There’s a performance upside too: \(\rho\)-less speeds up inference, with faster token sampling and shorter generations.
The takeaway? When we ground LLM decoding in information theory, we get a method that’s both systematic and highly effective in real-world use.