Q2 2025
Beyond linear steering: Unified multi-attribute control for language models
Controlling multiple behaviors in large language models (LLMs) is a challenging problem because different attributes can interfere with each other. Current linear steering methods are limited as they assume that behaviors can be simply added together in the model's activation space, which is often not the case. Additionally, these methods are inefficient, requiring a separate, dedicated tuning for each individual attribute, making them difficult to manage and scale for complex, multi-faceted control.
To solve this, a new approach called K-Steering has been developed. It uses a single, non-linear classifier trained on the model's internal states to dynamically compute new intervention directions via gradients. This approach is more flexible and powerful because it avoids the restrictive assumption of linearity and removes the need for storing and tuning separate attribute vectors. K-Steering allows for the dynamic and flexible composition of multiple behaviors without any additional training, providing a unified and efficient solution for controlling LLM outputs
Research submission here.
Calculating uncertainty in generative AI
Uncertainty is intrinsic to machine learning and AI applications. During model training, uncertainty can be propagated into the model in many ways. They include noisy data, data that’s limited in describing full data variability (such as part of a huge dataset or data collected from an infinite stream of data), a model that is too large for a non-complex prediction task, which causes parts of it to be unnecessary, and even model training algorithms that don’t achieve the best model parameters. While these factors can be mitigated, they cannot be removed. Therefore, the ability to quantify a model's uncertainty is crucial for evaluating its reliability.
Uncertainty in a model refers to how unsure the model is about its output, also known as its prediction, for a given input. Uncertainty can be represented by the variability in the model’s prediction — in other words, the range and frequency of possible outputs for a given input. Another concept that is similar to uncertainty is confidence, which relates to the probability of a specific output, such as the output having a confidence of 60% for a particular class Y out of a number of classes. Overall, uncertainty is a more informative metric than confidence as it considers the full output distribution instead of specific output probabilities.
Two fundamental uncertainties
There are two fundamental types of uncertainty when dealing with AI models.
Statistical uncertainty: Sometimes called aleatoric or irreducible uncertainty, This is caused by the inherent randomness within data; while it’s hard to remove, it can be reduced by increasing the accuracy of the data measurement and collection methods.
Epistemic uncertainty: Also known as model uncertainty or reducible uncertainty, This is caused by gaps in data from outside the knowledge boundary of the model. Determining epistemic uncertainty can be challenging as large models use vast training data that can’t be completely curated. That makes it difficult to delimit the model’s knowledge boundaries. However, this uncertainty can be reduced by techniques such as data augmentation.
Besides statistical and epistemic uncertainty, there are others worth noting. These include uncertainty introduced by model assumptions, such as model size and model architecture that are not perfectly suited to the task at hand. Hence, uncertainty estimation helps us assess the overall reliability and robustness of the model. We can then understand potential errors associated with the model’s prediction and the risks should we adopt the predictions.
Uncertainty estimation is useful in domains like healthcare, space, finance and defense where it’s particularly important for decision-makers to make sound judgments. Finally, user trust is enhanced by quantifying uncertainty in predictions made by generative AI applications such as large language models (LLMs). An example would be to draw a knowledge boundary around the internal state of the LLM to mitigate potentially hallucinatory outputs.
Challenges to uncertainty estimation
The LLM ecosystem is diverse. LLM frameworks vary greatly by design, implementation, compute needs and usage; these factors invariably affect how the entire model’s uncertainty should be accurately quantified.
In the following table, we show a categorization of modern LLMs and their unique challenges to uncertainty estimation.
| Models | Challenges to Uncertainty Estimation |
| Open model | Open access to model weights, gradients and outputs such as intermediate outputs and logits. Comprehensive uncertainty estimation is possible with full model access. While the training data and training algorithm is useful for uncertainty estimation, they may not be released. Examples: Gemma and Llama models
|
| Transformers | Hugging Face provides a standardized interface to fine-tune, evaluate and deploy models starting from pre-trained models. The specificity to pre-implemented models makes uncertainty estimation more challenging to integrate. Examples: Hugging Face pre-trained models GPT-2, BERT, etc.
|
| Proprietary | Black box with no access to model internals. Ensemble modelling and uncertainty estimation are hard due to the API's limitations for probing the underlying models. Examples: GPT-3.5, GPT-4, DALL-E-3, etc.
|
| Multimodal | Multimodal inputs combine text, visual, audio or more modalities. This increases the complexity of uncertainty estimation due to varying modalities contributing differently to uncertainty. Additionally, the outputs can be multimodal as well, compounding the difficulty in uncertainty estimation. Examples: Gemini-2, GPT-4, Flamingo etc.
|
| Distributed | Designed for large-scale, parallelized model training and deployment. The specificity to distributed workloads can introduce variability to model states and intermediate outputs, thereby complicating uncertainty estimation. Examples: PyTorch Lightning, Fairscale, Horovod, etc.
|
Quantifying uncertainty in models
The uncertainty of the prediction in simple models, such as linear regression and classification models, are straightforward to quantify. On the other hand, deep neural networks (DNNs) are models with a large number of model weights. They have multi-dimensional, multi-layer and sophisticated architectures for learning from large datasets and achieving high performance on complex problems. As a result of this complexity, quantification of prediction uncertainty in DNNs is less tractable. Therefore, quantifying uncertainty for DNNs is more complicated and computationally intensive, so approximate methods need to be used instead.
To illustrate uncertainty estimation of a simple model, consider a linear regression model with uncertain parameters:

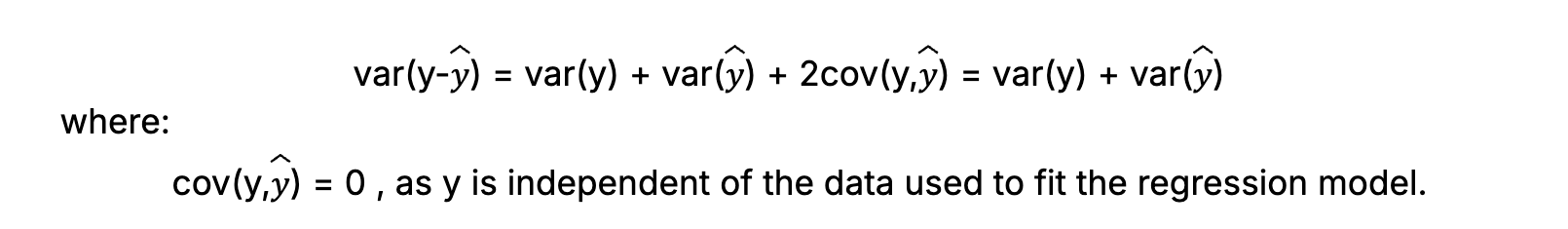
As shown above, the uncertainty derivation for a simple linear regression model is straightforward. On the other side of the spectrum, given a DNN with a complex architecture, diverse functions and a large number of layers and parameters, uncertainty compounds along the model and would be analytically intractable.
In this post, we will be walking through one practical and cost-effective method for uncertainty quantification: the dropout method.
Before jumping to the dropout method, let’s first familiarize ourselves with the Bayesian Neural Network.
Representing model uncertainty using Bayesian neural networks
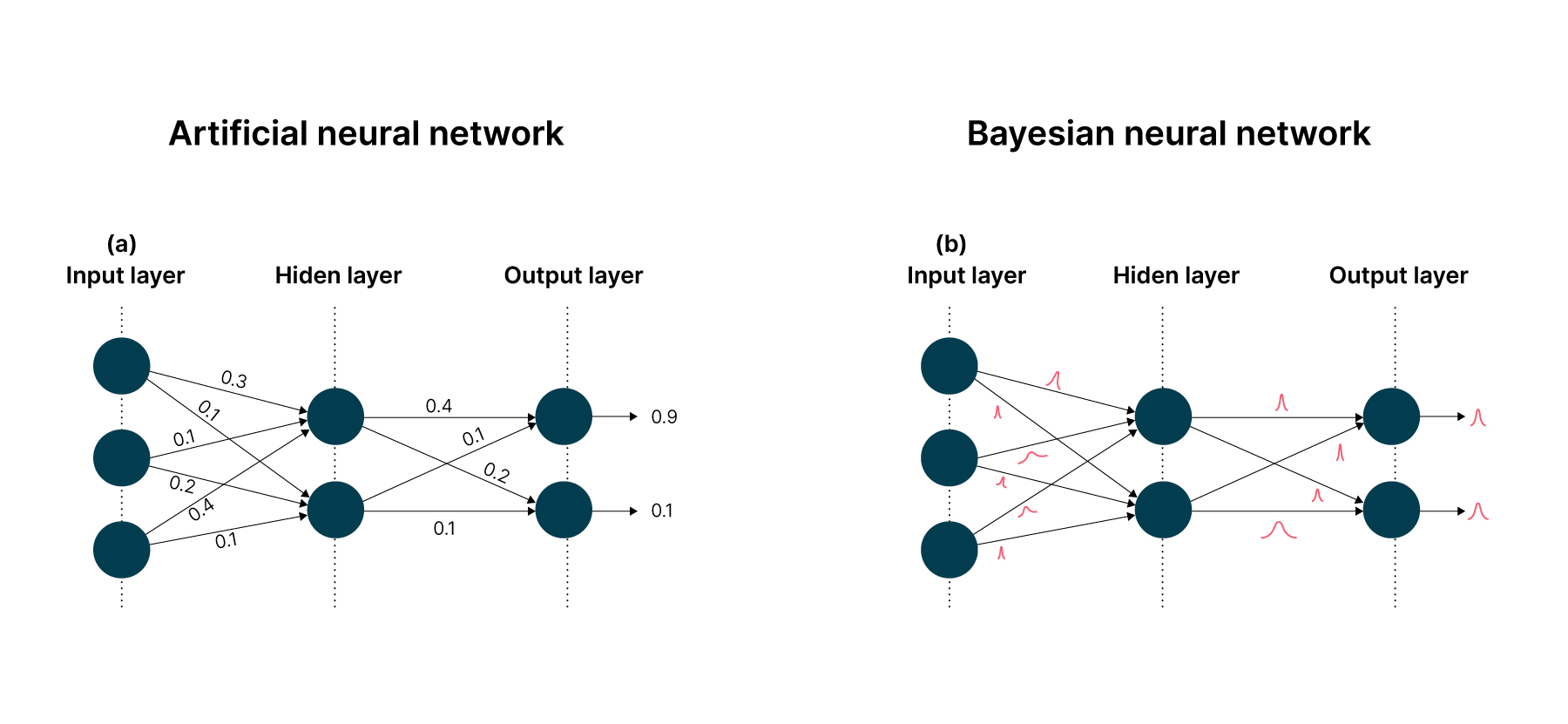
The synapses of ANN represent single valued weights and the synapses of BNN represent probabilistic distributions.
Many uncertainty estimation techniques are based on the mathematical foundations of Bayesian theory. Bayesian neural networks (BNNs) are networks where the weights W are treated as random variables and have a prior distribution p(W) instead of fixed values. This notion is a cornerstone of Bayesian inference; it reasons about the continual collection of data to update the range of weights and their likelihoods. This captures the uncertainty in weights, which in turn propagates to prediction uncertainty.
The Bayes’ theorem is as follows:

By marginalizing p(y|x,w) over the posterior p(w|D), the BNN considers all possible configurations of the network weights and their probabilities in making predictions. Although the Bayesian method is theoretically robust, as we see in this example, the computing costs needed by a BNN to directly compute the posterior distribution are high and prohibitive.
Fortunately, a technique that mitigates this challenge is the dropout method. It replaces the intractable problem of learning the original BNN’s posterior weight distributions with learning the weights of a representative neural network with dropping out applied to its weights.
The dropout method
Dropout refers to the random dropping out of weights of a neural network. The technique makes use of a simple distribution q(w) to approximate the true posterior distribution of the model weights p(W|X,Y). To achieve this, a distance between the two distributions, namely the Kullback-Leibler (KL) divergence, is minimized. Therefore, this method is equivalent to performing approximate variational inference. Now, connecting our chain of thoughts back to “Bayesian”, dropout can be interpreted as a variational Bayesian approximation technique.
In another view, dropout combines training multiple sub-networks of the original model and aggregates predictions from these sub-networks (each with randomly dropped weights from the original model) to approximate the overall model uncertainty; as such it can be regarded as an ensemble method. Also, dropout could drop neurons instead of weights to achieve a similar overall effect.
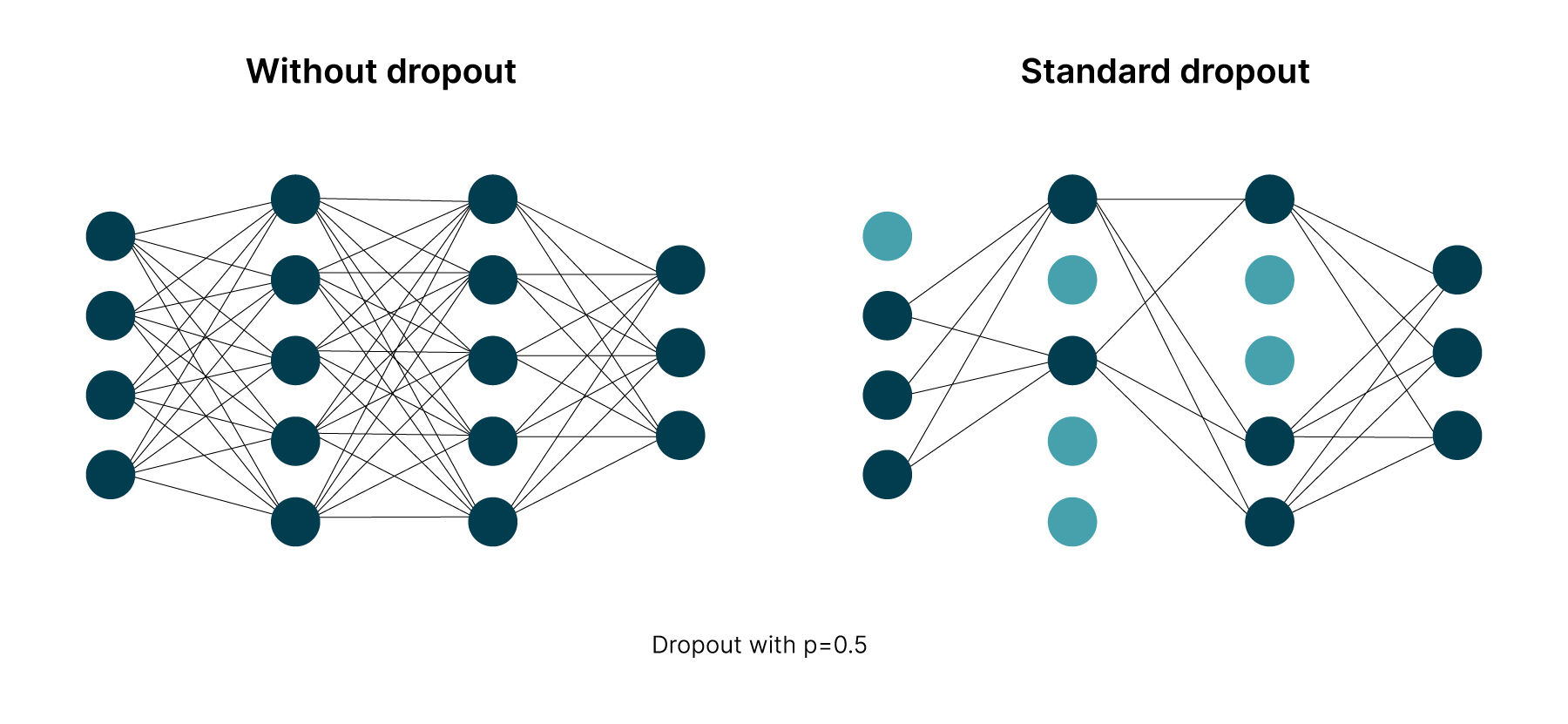
Practically, to implement dropout, neurons are randomly dropped with probability p in each training iteration that consists of a forward pass and a backward pass. Such neurons are deactivated, unable to contribute to the computations in the neural network for that training iteration, as shown by the network at the right of Figure 2. p is also known as the dropout rate. This behaviour is then repeated in all training iterations, achieving the overall effect of randomly thinning the original network during model training.
The comparison between a standard neural network and a dropout neural network is shown in Figure 2 and by the following equations.

Making inference with dropout

The overall equation represents two uncertainties: epistemic (due to insufficient data) and aleatoric (due to data randomness). It considers a distribution of predictions rather than a single deterministic output. The prediction made this way is more robust as it avoids over-relying on single point weight estimates and incorporates variability.
Estimating uncertainty
As we have seen earlier, T samples are collected in Equation three. Each represents a prediction given a sampled set of weights from the approximate posterior weight distributions. It turns out that the sample variance from the T samples can be computed to estimate how uncertain the model is about its prediction in the regression task. Briefly, for classification tasks the entropy of the mean probability vector (mean softmax outputs) can be used. This approach to estimating uncertainty is also known as Bayesian inference for uncertainty estimation.
Figure three shows two distributions of sampled predictions, followed with an explanation of how uncertainty estimation helps in decision making.
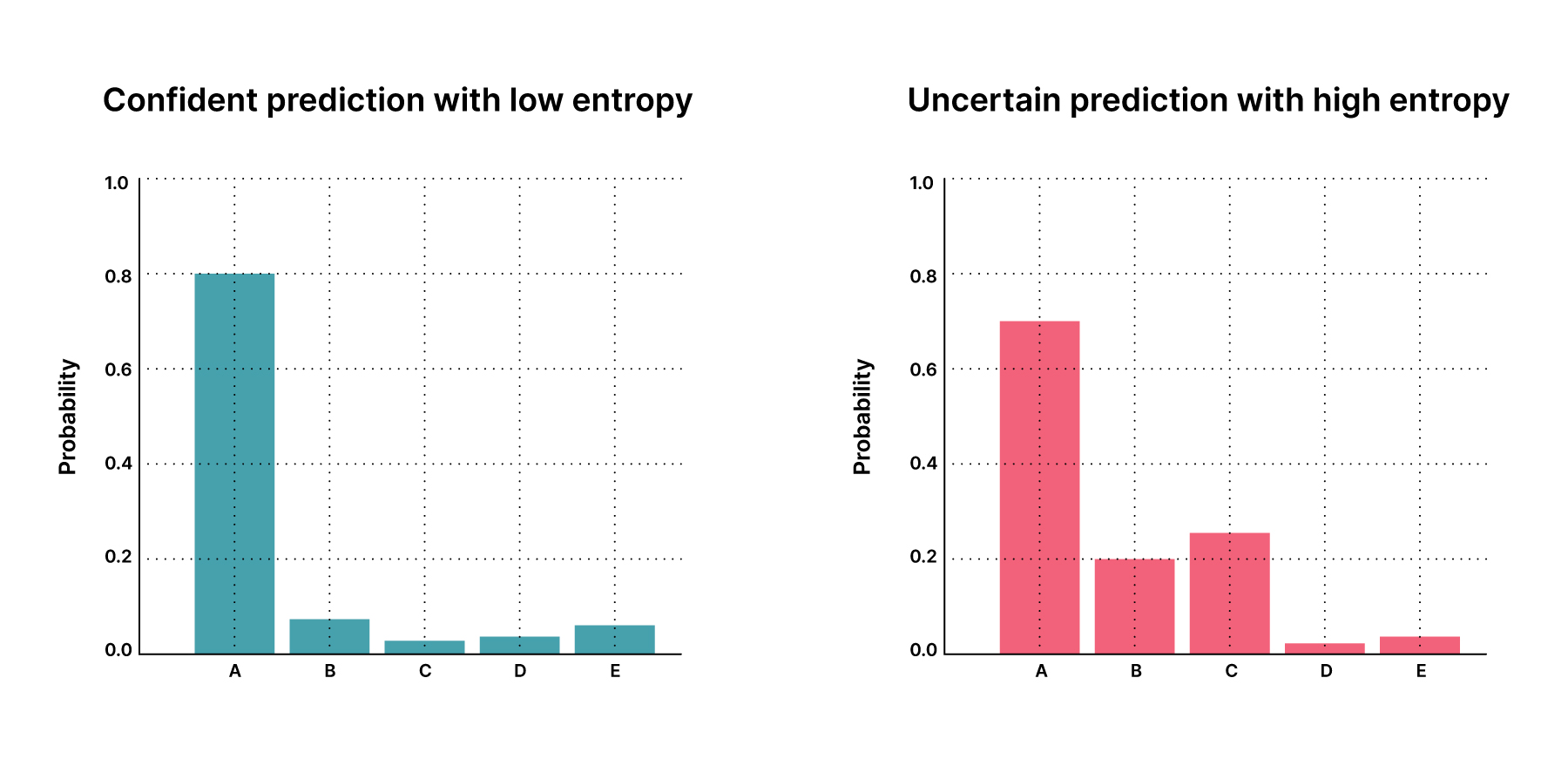
Confident prediction with low entropy (Figure 3: left chart in blue)
The mean probability distribution shows a sharp peak at class A as all sampled predictions agree strongly on class A (i.e. all softmax outputs peak highly at class A). Therefore the model is confident about its prediction and the entropy is low.
Uncertain prediction with high entropy (Figure 3: right chart in red)
The mean probability distribution shows significant spread over classes other than A. Even when the model assigns high overall probability to class A, the sampled predictions vary significantly (i.e. fluctuation of softmax outputs) and class A may not have been the class with the highest probability in all samples. Therefore the model is uncertain despite appearing quite confident on average, and the entropy is high.
The key insight is that when making judgments on predictions made by neural networks, it is generally inadequate to decide based on only the modal (highest probability) class. Rather, we should also consider the uncertainty associated with the prediction. While we could adopt a prediction having high probability and low uncertainty, it is crucial to perform a risk assessment on a prediction having high probability and high uncertainty.
Mitigating overfitting and co-adaptation
Large neural networks such as LLMs are trained on vast and complex data. During training, a large enough model could inadvertently learn the random noise inherent in the training data or even outliers. This results in overfitting. The model fails to generalize to unseen data, essentially memorizing the training examples (including the random noise and outliers) instead of adequately learning the underlying patterns and relationships within the data. As a result, it performs deceptively well on the training data but becomes unreliable in making inferences on new input data.
A large enough model could also be more susceptible to learning highly correlated behaviours amongst its weights, a phenomenon termed co-adaptation. When this happens, the weights do not capture independent but inter-related features and less useful narrow features. Consequently, when one neuron receives a low quality input leading to an inaccurate output, the co-adapted neurons, being highly-correlated, are likely to be impacted as well. Overall, this leads to a loss of generalization ability.
Dropout is one type of neural network regularization methods to reduce model overfit and co-adaptation. Dropout nullifies a random set of neurons in every training iteration, such randomness disrupts any memorization that could potentially take place in any neuron, thereby preventing model overfit to specific training examples. In addition, since a different network structure is realized from every dropout configuration sampled, the network distributes the learning of important features over a larger number of neurons. This redundancy enhances the model’s generalization to unseen data. Finally, as neurons are randomly dropped, co-adaptation between them is broken and they are encouraged to learn useful independent features, resulting in a more efficient model. The model also becomes more robust, not failing on specific feature interactions that do not hold well beyond the training data distribution.
Conclusion
In this post, we demonstrated how dropout can be a practical and more cost-effective method than BNNs for estimating the model’s prediction uncertainty given an input. In particular, the sample variance of a number of predictions from the given input can be computed to estimate how uncertain the model is about its regression task; while for classification tasks the entropy of the mean softmax outputs can be used. Finally, besides uncertainty estimation, dropout had been shown to be effective against overfitting, allowing the model to generalize better to unseen examples than models trained without dropout.
The next frontiers in AI — according to industry leaders
Trying to follow changes in the world of AI — and generative AI in particular — is challenging. However, AI events and keynote speeches in particular are exceptionally useful for understanding the key narrative threads and emerging trends.
Based on watching a number of keynotes from the last nine months or so, the key trends we think are particularly important are:
The possibility that LLMs are an ‘off-ramp’ on the path to artificial general intelligence (AGI).
Alternatives to transformer-based architectures.
Hardware innovation and AI evolution.
The mainstreaming of agentic AI.
Open-source AI.
Physical AI and world models.
Let’s take a look at each of these in more detail.
Are LLMs an off ramp on the path to AGI?
While LLMs have been the main focus of attention when it comes to AI today, researcher Francois Chollet has suggested that they’re something of a distraction when it comes to the bid to create artificial general intelligence (AGI). Speaking on the Dwarkesh podcast, he argued that “OpenAI… set back progress to AGI by five to 10 years.”
While Chollet’s claim might sound combative, Meta’s Yann LeCun defended his argument. Speaking at NVIDIA GTC 2025 alongside NVIDIA’s Chief Scientist Bill Dally, he said:
“Today’s LLMs are typically trained by 30 trillion tokens. Each token is typically three bytes long. So in total there are 10¹⁴ bytes. This will take any average human nearly 400,000 years to complete the reading - the content of the entire internet. A psychologist believes that a four year old is awake for nearly 16,000 hours in its life. It transfers ~ two Mbps of data to the visual cortex through the optic nerve. If we multiply this by 16,000 hours times 3600 (seconds of an hour), then it is roughly 10¹⁴ bytes in four years through the vision. So we “see” as much data as text that would take us 400,000 hours to “read”! It means that we will never reach AGI by training LLMs from text-only data.”
Yann LeCun
Chief Scientist, Meta
In other words, LLMs are insufficient in the pursuit of AGI. Of course, whether AGI is desirable or, indeed, if it’s possible at all, are other debates to be had, but what matters is that current interest in LLMs certainly won’t be the start of a path towards anything resembling AGI.
Alternatives to transformer-based architectures
Transformer-based architectures dominate the AI landscape. This is because of their attention mechanism, which has several strengths, including scalability, parallel processing tokens, fine-tuning for domain-specific data and handling multimodality.
However, they nevertheless have some significant limitations:
They’re quadratic in context length, which is compute-intensive and slow.
Interactions between tokens are restricted to pairwise attention via dot products, which limits the model’s ability to represent higher-order relationships.
They lack any mechanism for combining multiple tokens into higher-level abstractions or complex interactions.
These limitations are leading to a resurgence in alternative paradigms, most notably Long Short-Term Memory. More specifically, we’re seeing something called Matrix Long Short-Term Memory (mLSTM). These are versions of LSTMs that apply matrix-based memory representations, which makes them not only faster but also more energy-efficient than transformer models. They address several scalability and latency challenges that AI developers and researchers are trying to overcome.
Speaking at NeurIPS at the end of 2024, Sepp Hochreiter — the inventor of LSTM — highlighted the urgency of rethinking how AI systems think. He called for models that actually deliberate before producing an output. He spoke, for instance, of “a new series of AI models designed to spend more time thinking before responding is the need of the hour. The high speed of inference will matter in the future.”
xLSTM-7B, a state-of-the-art open-source model, exemplifies this shift. As one of the most promising transformer alternatives, it may shape the next phase of generative AI design.
The foundational AI hardware of the future
Generative AI's progress is deeply rooted in hardware innovation. In the last ten years, computational power has increased dramatically — by factors ranging from 5x to 10,000x. This has enabled breakthroughs in both model training and inference. Advanced reasoning approaches like Chain of Thought, Best-of-n sampling, path planning, and consistency validation have succeeded largely due to this exponential leap in computation.
The shift in architectural strategy — from scaling out to scaling up — has delivered transformative gains in performance. Today, the computational load required for agentic AI and complex reasoning is estimated to be 100x more than previously anticipated. Meeting this surge in demand, leading cloud providers — AWS, Azure, GCP and OCI — have already deployed a combined total of 1.3 million Hopper GPUs and 3.6 million Blackwell GPUs, with rapid expansion still underway.
On the other hand, we are witnessing the peak of what digital CMOS (Complementary Metal Oxide Semiconductor) technology can offer. After decades of refinement, it now delivers extraordinary compute power with massive capital efficiency. Google’s next-generation TPUs exemplify this evolution — offering a 3,600x increase in compute compared to their 2018 predecessors. The latest TPU pods pack over 9,000 chips, driving 42.5 exaflops per pod while using 29% less power built specifically to meet the rising demands of generative and agentic AI. To contextualize, that’s 24 times more performance than today’s leading supercomputer.
Yet, as we look beyond CMOS, the next frontier could be neuromorphic computing — hardware modeled on the architecture of the brain. Spiking nets, the biological blueprint of our cognitive systems, communicate through binary spikes, offering the potential for energy-efficient, event-driven AI.
But the promise comes with significant technical challenges. Unlike digital systems, analog neuromorphic chips cannot multiplex, requiring one physical neuron for every virtual neuron. Given the scale of modern AI models, building such systems on a single chip is impractical. Scaling across chips introduces even more complexity, reducing system efficiency and reliability. In short, while CMOS remains dominant today, the seeds of post-silicon computing are being sown.
In pursuit of scalable, AI-first infrastructure, Google has announced a $75 billion capital expenditure aimed at strengthening its AI server fleet and cloud backbone. The initiative accelerates an open, interoperable multi-cloud platform, where AI agents can integrate directly into enterprise environments — interfacing with legacy databases, business applications and external AI models. Notably, by the end of 2025, cloud infrastructure will lead the market by adopting NVIDIA’s cutting-edge Vera Rubin GPUs, offering 50 petaflops of FP4 inference performance, setting a new standard for real-time AI performance at scale.
The open-source AI revolution
Turning innovation in AI into truly impactful technology requires robust compute- infrastructure. In turn, that requires substantial capital investment.
The future of foundational AI lies in open-source consensus models, collaboratively trained across distributed global data centers, each with access to distinct datasets. This approach allows for decentralized, transparent, and inclusive development of AI models, enabling richer capabilities and reducing monopolistic control over foundational AI technologies. These models will enable flexible adaptation across vertical industries.
A case in point is Isaac Groot N1 — a recent open-source humanoid intelligence model developed jointly by NVIDIA, Google DeepMind and Disney Research. With built-in reasoning and a next-generation Newtonian physics engine, it is a benchmark for AI-human embodiment. As open-source platforms scale, they may outlast proprietary stacks, especially in the development of multilingual LLMs that cater to culturally and linguistically diverse populations in real time—ushering in a new paradigm of globally accessible AI.
Extending this open-source momentum, frameworks like the Agent Development Kit (ADK) are central to the rise of agentic AI. ADK enables the creation of multi-agent systems with modular ease and supports the Model Context Protocol (MCP) — a standardized approach allowing AI models to access and operate across diverse tools and data sources efficiently.
Today there are a few prominent open-source Generative AI models across different domains:
Text generation: Mixtral 7B by Mistral, LLaMA-2 by Meta, and Phi-2 by Microsoft
Image generation: Stable Diffusion by Stability AI, and Kandinsky 2.2 by Sberbank
Video and animation: ModelScope by Alibaba DAMO
Agents everywhere
The trajectory of computing has evolved — from retrieval-based paradigms to generative models and now toward agentic computing, a domain centered on autonomous reasoning. This transition marks the rise of agentic AI, where decision-making and contextual understanding take precedence.
Speaking at an AI conference in February 2025, Andrew Ng, DeepLearning founder, talked about this at length.
Specifically, he highlighted that software agents are at the core of this model. They exhibit sophisticated behaviors: strategic planning, causal reasoning, persistent memory and adaptive tool use. They are capable of multi-step execution and collaborative task completion. Currently, five agent types are already proving transformative in enterprise and operational settings.
Customer agents are multimodal systems that understand and reason across text, audio, images and video. They engage in natural conversations, integrate with enterprise systems and act on users’ behalf — appearing in contact centers, devices, websites and vehicles. For example, Google's Contact Center
Creative agents assist in artistic tasks by generating ideas, supporting prototyping and speeding up content creation—helping reduce production time and accelerate time-to-market. For instance, Runway’s Gen-2 enables video creators to generate scenes from text or still images, cutting down visual effects production time.
Data agents identify relevant data, frame the right questions and activate insights. Tools like BigQuery unify structured and unstructured data using open formats such as Apache Iceberg. These agents support roles from data engineers to analysts across storage systems and cloud platforms. Example: Google Cloud's Looker Studio uses AI agents to suggest visualizations and explore data automatically.
Coding agents help write, debug and maintain code. AI tools like Gemini, Aider, Cursor and GitHub Copilot streamline software development — from prototyping to production and maintenance. GitHub Copilot, for example, auto-suggests code snippets as developers type, speeding up implementation and reducing errors.
Security agents handle malware detection and threat analysis, as well as real-time alert triage to strengthen cybersecurity operations. Microsoft Security Copilot helps analysts identify, prioritize, and respond to cyber threats faster using threat intelligence and language models.
Today’s agentic AI is still in its early stages but already exhibits four emerging design patterns: reflection, tool use, strategic planning and multi-agent collaboration. Looking ahead, self-improving AI agents are no longer science fiction — they are an imminent and plausible reality.
Physical AI
The logical successor to agentic AI is physical AI — intelligent robotic systems capable of perceiving, reasoning and acting in the real world. Unlike software agents confined to digital domains, robots bring cognition into physical form.
Speaking at NVIDIA’s AI Summit in India in October 2024, Jensen Huang forecast that by 2030, a global labor shortfall of at least 15 million will be offset by general-purpose robots, marking the arrival of physical AI at industrial scale.
Training these systems poses significant challenges. Unlike LLMs, robots require control and action data, which is costly and time-consuming to acquire. To overcome this, developers must collect real-world sensor datasets and expand them through synthetic data generation. These synthetic environments are then used to train robot policies through imitation learning or reinforcement learning. However, synthetic success must translate to the real world. This demands rigorous validation via digital twins, simulating dynamics, sensors, and environmental variability using software/hardware-in-the-loop testbeds before deployment.
Collaboration among multiple robots is becoming central to robotics, powered by shared post-training policies. The field is advancing toward generalist humanoid foundation models trained on synthetic data and simulations. Meanwhile, robots themselves are generating synthetic data to pre-train AI models — flipping the traditional pipeline.
Inspired by human cognition, slow thinking lets robots understand and plan, while fast thinking enables fluid, real-time action.
AI architecture is changing due to falling compute costs. GenAI's processing ($40/GB) used to dominate over data transfer (~$0.10/GB), but hardware advances now enable distributed small language models (SLMs), fostering modular, decentralized software architectures. This amplifies the role of data engineering, particularly for large-scale unstructured content.
In the near future, professionals like recruiters, marketers and financial analysts will use GenAI to amplify productivity by an order of magnitude — coding, analyzing and deploying smarter tools.
However, AI misuse remains a concern—deep fakes and disinformation can cause real harm. The solution lies in reasoning-capable AI that can evaluate the trustworthiness of its own outputs.
AI factories
In the same talk at AI Summit in India, Huang also argued that we’ve entered a new era in computing. This future, he went on to claim, requires radical rethinking as we move away from hand-crafted software on general-purpose machines toward machine learning-driven software executed on GPUs and dedicated accelerators.
Future systems, he said, will not rely on traditional programming. Instead, they will generate tokens. These AI-driven systems, or “AI factories,” will operate on the next-generation of open-source operating systems which will have been purpose-built for autonomous software generation.
An AI factory, according to Huang, is a data center optimized for AI. It ingests data, trains AI models to output new models, decisions, services or products. Jensen Huang claims data is the new raw material, and AI models are the new products.
Key components of AI factories:
Data as the raw material. Just as factories use raw materials, AI factories consume large-scale data to produce intelligence.
Massive computing power. AI factories will be powered by GPUs (like H100s), optimized for large-scale model training and inference.
AI infrastructure software. An AI software stack (e.g., NVIDIA AI Enterprise, DGX Cloud, CUDA) will be used to manage and accelerate workloads.
Model training and deployment. AI factories will take a key role in creating foundation models and deploy them across various domains.
Automation and orchestration. AI workflows will be highly automated, with software managing data pipelines, training cycles and deployment.
Scalable outputs. The end product will be either generalist or specialist AI that can power apps, robots, digital twins and enterprise solutions.
However, sceptics point the following pitfalls on the concept and operation of AI factories:
Over-reliance on GPU-centric architectures.
“Tokens as atomic software units” are not fully defined.
Autonomous software may lack accountability and robust safety measures .
Simultaneously, the world is witnessing a profound shift in data center strategy. It’s no longer about how many data centers are built, but instead how they are powered. In a world where every facility is constrained by power, energy becomes the currency of compute. Revenue is now tightly coupled with available electrical capacity, positioning computing squarely as a power-limited industry.
Joint Embedding Predictive Architecture (JEPA): An innovative new approach
In biological systems, ‘world models’ represent mental simulations of the physical world. They’re used to anticipate outcomes, plan actions and reason about environments. Joint Embedding Predictive Architecture (JEPA) is a self-supervised learning framework that distinguishes itself by predicting abstract representations rather than predicting the next token. In AI, world models are gaining traction as a potential successor to LLMs, offering a more generalized and grounded approach.
LeCun points out that many real-world phenomena are unpredictable at fine-grained levels. Models that attempt pixel-level prediction often fail by generating implausible detail. Thus, using self-supervised learning to predict video frames directly is not viable—unless the system learns at the level of abstract representations.
JEPA utilizes self-supervised learning and energy-based models to predict abstract representations of future states, focusing on the underlying dynamics and structure of the world. This approach contrasts with large language models (LLMs), which primarily rely on statistical patterns in text data to generate tokens.
“Within three to five years,” LeCun said, “we’ll have a much better paradigm for systems that can reason and plan”.
Keeping your eyes on the AI horizon
There’s lots happening across the AI industry; trying to summarize it effectively would be immensely difficult — even with an exceptionally effective LLM! However, there are clearly some key throughlines: from model architecture and hardware to the industrial application of AI, innovation and experimentation is happening on a number of different fronts.
Anyone that’s been trying to stay on top of this exciting field will know all too well just how challenging it is; it’s probably only going to get harder in the years to come. However, at their best, industry events provide a valuable glimpse into what leaders think is important and where they think our attention should be focused. While there’s undoubtedly always commercial imperatives somewhere in their pronouncements, it’s still worth listening with both critical distance and an open mind.